Oppsummering fra KORG dagene
mars 14th, 2012Her kommer litt oppsummering fra KORG dagene!
Hilsen Ellen, Irene, Anne Å og Aud
 No Comments » |
No Comments » |  KORG |
KORG |  Permalink
Permalink
 Posted by bubag
Posted by bubag
Her kommer litt oppsummering fra KORG dagene!
Hilsen Ellen, Irene, Anne Å og Aud
No Comments » | KORG | Permalink
Posted by bubag
… Oss kontrollfrikere imellom:
Library of Congress har kommet med en erklæring om at fremtiden til bl.a. MARC21 må revurderes.
Nye tider har strammet inn på katalogiseringsbudsjettene rundt om, samtidig stilles det større krav til bibliografiske data enn noensinne (fritt oversatt).
«Cultural heritage institutions see their resources dwindling at the same time that they need to invest in dramatic new uses of bibliographic data. In this environment, many institutions have been forced to relax standards of quality in bibliographic records while still being asked to broaden their services, especially in terms of the availability of digital data.
Efficiencies in the creation and sharing of cataloging metadata are therefore imperative: information providers and cultural heritage institutions must reevaluate their use of scarce resources, both as individual organizations and as a community.»
Det litt vittige er forresten at akkurat de samme tingene var begrunnelsen for FRBR-rapporten, da den kom i 1998.
Går utifra at både form og innhold må vurderes mht hvordan vi katalogiserer, og det er jeg helt sikker på at LC kommer til å gjøre. Ellers er det jo mange som er veldig opptatt av
selve MARC-formatet, og vil dets død. Her er noen argumenter som stadig høres, jeg kommenterer i parantesen.
Jeg synes mye høres vanskelig ut i denne forbindelse, men min enkle oppfatning er noe sånt som:
På webben trenger vi noe som er enklere å fortolke for en datamaskin. Koder som viser at her begynner denne opplysningen, og her slutter den. Koding som viser hvilke opplysninger som hører sammen, og hvorfor de hører sammen (relasjoner). Og vi trenger entydige opplysninger; mer standardisering.
Mye informasjon ligger implisitt i en MARC-post, men den samme informasjonen bør gjøres eksplisitt. At (alle?) opplysninger på en katalogpost hører sammen, er en type implisitt imformasjon. At 100-tagen forholder seg til 245-tagen er implisitt. At kanskje over 95% av alle 100-tagger er en forfattertag ligger implisitt. Men om 100-taggen også har en kode «aut» i $4, er det både sikkert og eksplisitt at her er det en forfatter det er snakk om.
Om en 700-tag har kode «edt», så vet vi at her er det (høyst sannsynlig) snakk om en redaktør til den boka som har tittel på samme post som er registrert i 245. Men om det ikke står noen kode i en 700-tag, så er det ganske mange relasjonsmuligheter.
Om noen har glemt 700 $a og $t og i stedet brukt 700 og 740 så er det duket for trøbbel (de som skjønte dette tilhører ”stammen”).
På en katalogpost står de fleste taggene (MARC-feltene) i ett eller annet forhold til resten av feltene. Men forholdet er ikke alltid like opplagt som det er med 100 (forfatter) og 245 (tittel). (Stammespråk: 700, 740, 500, for ikke å si 600, kan være problematiske. For ikke å snakke om 691 !! )
Går utifra at LC vil se på alle disse tingene. Og håper de legger vekt på å få frem HVILKE opplysninger er så viktige at de må kunne entydig tolkes og utnyttes av en datamaskin.
Det er tross alt noe med at AACR2 ikke får tydelig frem om vi bør være mer pinlig nøyaktig noen steder enn andre.
Håper LC analyserer hva som er «pirk» og hva som er standardisering. (Foreslår to kolonner slik at det kommer klart fram 😉 )
Det er iallefall flott at LC vil granske både RDA, MARC-21 i forhold til hva de mener vi trenger av bibliografiske data fremover.
Det som er litt uklart for meg, er hvordan LC skal kunne klare å slå alle fluer i en smekk:
Behovet for mer entydige data, behovet for mer detaljerte data, behovet for mer eksplisitt kodete data, behovet for konvertering til mer datavennlige data, behovet for enklere gjenbruk og mekking på andres data OG behovet for mer rasjonalisering pga strammere økonomi.
Det blir spennende å se hvor vi havner. Nå skal jo vi også straks over til MARC-21 fordi vi har fått et nytt
biblioteksystem. Man er jo nesten avmodernisert før man har begynt!
Men trøsten er at dersom vi får dataene våre mer eller mindre velberget over til MARC-21, så blir vi i neste runde med på en kyndig styrt masseovergang til noe nyere og bedre.
PS1. I Trondheim er det en lek der du holder en haug med sand i hånden, snur hånden og sanden havner på håndbaken. Du snur hånden igjen og igjen, mens du sier:
”Så my hadd æ, så my ga æ bort, så my mista æ, og så my fekk æ igjen…”
Av en eller annen grunn får ”datakonvertering” meg til å få den assosiasjonen. Men det var en total digresjon.
PS2 innledningen her var en festlig spøk.
Jeg er veldig veldig klar over at det er mange av oss som er blitt bibliotekarer for å kompensere for alt
det vi ellers roter med.
Sigrun
2 Comments | KORG | Permalink
Posted by bubak
Jeg slumpet nettopp over en side med oversikt over søkbare felt og delfelt i World Cat.
Noter ER faktisk allerede søkbare i fellesbasen i WorldCat, rubbel og bit 😮

nt: Lille Persille gir f.eks. 4 treff.
Her er oversikt over
World Cat søkeindekser.
Interessant å vite når man planlegger migrering.
Å søke med kommandoer er ikke akkurat publikumsvennlig, men det er kjekt å kunne for oss i skranken.
Dette var søkeindeksene til fellesbasen World Cat. I World Cat Local kan man tilpasse søkemulighetene til egen base.
Nå gikk jeg ikke akkurat hit for å finne ut om noter var søkbare, det var mer emnefeltene jeg skulle sjekke vilkårene for.
Sigrun
1 Comment | KORG, Ukategorisert | Permalink
Posted by bubak
Det er nettopp blitt mulig å logge seg på 2.0-versjonen av WebDewey (rull ned under DDC 23).
2.0 versjonen har en bedre layout, og – obs obs- det er mulig å legge på kobling mot mange kataloger. Det er også fint mulig å direktekoble seg mot emneregistrene i BIBSYS.
Kobling mot flere OPAC-er foreslo jeg faktisk for OCLC den gangen de bad NKKI om innspill til ny WebDewey. Kanskje dette er takket være meg? 😮 Sikkert ikke, men det er snedig.
Default kobling er mot LC. Men du kan legge inn ubegrensete nye koblinger. På mitt passord har jeg nå lagt inn søk mot BIBSYS Ask (OPAC 1) + søk i UBB sitt emneregister (OPAC 2) + UBO sitt emneregister (OPAC 3). Tror man kan legge inn så mange man vil.
Da kan du altså stå på et hvilket som helst deweynummer, og klikke link to OPAC … Og på direkten sjekke hvordan f.eks. UBB eller UBO tidligere har brukt det nummeret du lurer på om du skal velge.
Det funker selvsagt i den grad emneregistrene er oppdatert. Men slike hjelpemidler er vel unnværlige dersom man skal ha sjanse til å komme i nærheten av en felles klassifikasjon?
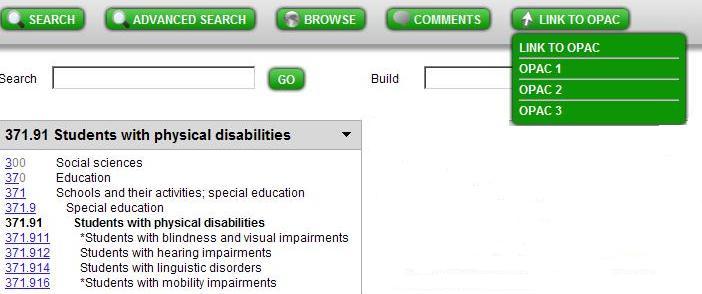
Ellers virker 2.0-versjonen fortsatt ikke helt hundre prosent stø.
Sigrun
No Comments » | KORG | Permalink
Posted by bubak
Spennende KORG-dager i Oslo sist uke, med masse tankestoff. Hele forsamlingen lærte hva «tripler» er. Og vi skjønte hvorfor tripler med urier er viktig for Linked data.
Kim Tellerås og David Massey hadde en innføring som er verdt å kikke på.
Se RDF og Linked data – en praktisk innføring .
Må vel tilføye at det virket enkelt sist fredag, men det er ikke det når man begynner å tenke på det. Hvor skal f.eks. uri-ene egentlig gå til?
Det vil jo variere fra katalog til katalog, men har vi noen steder å lenke til?
URI på Dostojevskij i BIBSYS, f.eks. skal vel vise hit hit etterhvert
Men bok, eller «verk» da?
.. Og klarer vi å holde rede på alle relasjonene når frbr blir blandet inn i dette..
(Og er det virkelig nødvendig å gjenta alle relasjoner på hver eneste katalogpost? Er det ikke noe som heter arvede egenskaper… ?)
Karen Coyle er en person som skjønner det meste av katalogisering. Hun forklarte oss RDA og Linked Data meget pedagogisk. Og hun viste til hvordan de har gjort tingene i «Open library», det er verdt en kikk.
Her er det hentet inn data fra andre kataloger, Wikipedia osv, og sammenstilt. Se f.eks. hvordan publiseringskurven er for emnet «dogs»:
Må også nevne at vi skjønte at RDA ikke er bare bare, men snarere noe å gå i protesttog mot. Kanskje med Unni Knudsen og Karen Coyle i spissen.
Men det jeg egentlig tenkte å gjøre her var å referere hva som ble sagt om nytt biblioteksystem.
Ellen Røyneberg hadde en kjempebra, systematisk og detaljert gjennomgang. Den kommer nok snart på ppt, dette er «mens vi venter».
Fra Ellen Røyneberg: Status for nytt biblioteksystem
OCLC har full kontroll over utviklingen av det nye ILS. Bibsys kommer til å betale årlig leie for systemet.
BIBSYS kommer ikke til å ha noen reell innflytelse på utviklingen av produktet, men BIBSYS skal utvikle nasjonale tilleggstjenester, det vil bli et eget prosjekt.
Koordinering av disse to utviklingsprosjektene + konvertering av basen vil være et samarbeidsprosjekt mellom BIBSYS og OCLC.
Det skal også settes i gang et prosjekt «innføring av nytt system i institusjonene».
Systemet skal taes i bruk i 2013, og det vil bli fortsatt utvikling etter det. Systemet skal kunne gi enhetlig rasjonell håndtering av ulike dokumenttyper.
Innføring i institusjonene
En ekstern prosjektgruppe skal utforme de store linjene: Gi BIBSYS forståelse av utfordringene ved innføring av nytt system.
Det vil også bli satt ned større faggrupper som jobber med konkrete konsekvenser av det nye systemet.
Oppstart prosjektgruppe 3.kvartal 2011. De skal se på arbeidsflyt, behov for opplæring og likheter/ulikheter mellom institusjonene.
Status
Konsekvenser ved datamigrering
MARC21 – et framskritt?
FRBR-visning i World Cat
OCLC har innført begrepet «verk», men de har hoppet over «uttrykk».
Konvertering – spesielle forhold
Identifikatorer vil bli tatt vare på, som objektid, dokid, låntaker-id og id for autoriteter
Lenking
BIBSYS sin horisontale lenking kan ikke overføres til World Cat. Det utredes å bruke felt 773 fra MARC21. BIBSYS jobber for å opprettholde strukturen vi har.
Konverteringen
BIBSYS jobber for å selv ta ansvar for konverteringen.
Nasjonalt autoritetssystem
Er kommet i stand etter oppdrag fra NB. Versjon 1.0 blir ferdig dette kvartalet. Det er viktig å bevare koblingen mellom autoritetsregisteret og postene.
Nasjonalt autoritetssystem (autoritetsregister) er laget først og fremst som et verktøy for NB. Det er uklart hvor mye støtte det blir for det i det nye biblioteksystemet. Det er viktig at registeret kan samvirke med andre nasjonale autoritetsregistre.
Muligens ender Nasjonalt autoritetsregister opp som et eget utenforliggende system, som kan kobles opp mot biblioteksystemet.
I den første fasen jobbes det bare med personnavn. I senere faser kommer standardtitler og korporasjonsnavn.
Registeret blir også tilgjengelig som Linked Data via prosjektet «Rådata nå».
Sigrun
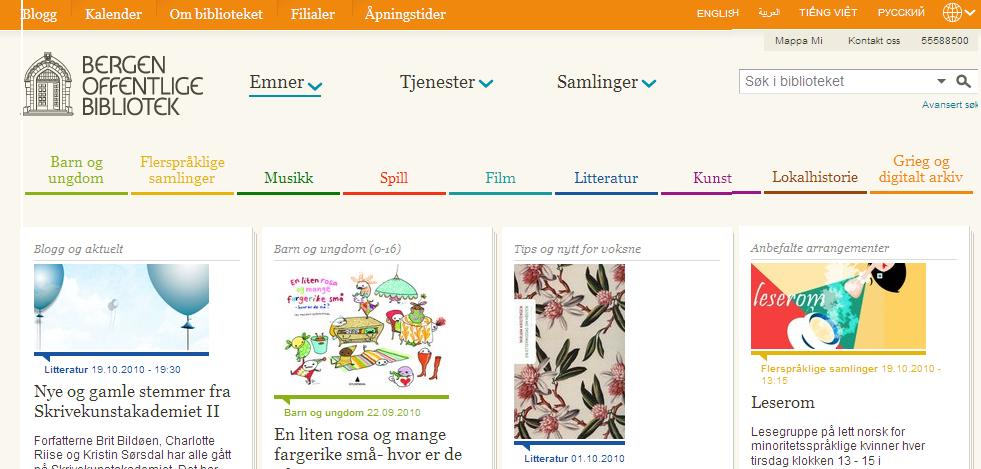 Bergen Offentlige bibliotek har fått nye hjemmesider .
Bergen Offentlige bibliotek har fått nye hjemmesider .
Det er mye letter nå å se hva de kan tilby, er det ikke? Og dessuten ser sidene hyggeligere ut enn de gjorde før.
Prøv å klikke på «russkij» øverst til høyre og se hva som skjer…
De har en google-lignende søkeboks for søk i katalogen.
Hurra, du blir kobla videre når du søker på hc andersen :-). 10 poeng til Bibliofil.
Men akk, det skjærer seg når du søker på Andersen, HC 🙁
Det er ikke lett å lage geniale søkebokser, bare å slå fast.
Ser at det nye bibliofil-grensesnittet viser fasetter i høyre marg, ok, det er vi vant til nå. Men Bibliofil viser avgrensingsfasettene med antall treff  Hvem sier at indekser ikke er noe for brukerne 😉
Hvem sier at indekser ikke er noe for brukerne 😉
Sigrun
No Comments » | KORG | Permalink
Posted by bubak
Det har vært en stor Linked-data konferanse i London.
http://www.iskouk.org/events/linked_data_sep2010.htm
Tror ikke noen på UB var på denne konferansen, men dette begrepet svirrer rundt oss. Her er et forsøk på en populær oppsummering av hva det handler om.
Linked data er mye omtalt i forbindelse med emnesøk, men det angår alle søkbare bibliografiske data som det er interessant å klikke seg videre på.
(F.eks har jo UBiT fått midler til å videreutvikle BIBSYS autoritetsregister som linked data.)
Linked data er i webbens «ånd» – world wide web-prinsippet er jo at man kan klikke seg videre.
Det har handlet om å klikke seg videre fra dokument til dokument stort sett, men nå handler det også om å kunne klikke seg videre via metadata.
Metadataene bør være entydige og de bør befinne seg i en meningsfull kontekst (eks forfatterdata med fødselsår og med titler tilknyttet navnet, emneord med definisjon, plassert i et emnehierarki).
Og vitsen med linked data er at man skal kunne klikke seg videre til andre entydige metadata som er satt inn i andre meningsfulle kontekster.
Linked data representerer etter min mening et gehør for det bibliotekarene har skjønt og holdt på med lenge, at emnedata/forfatterdata osv må være entydige og konsistente, ellers blir det bare rot.
Det er Tim Berners Lee som er guru mht Linked data.
Linked data handler om ting katalogfolket egentlig har holdt på med i evigheter tenker jeg.
Nemlig å sette bibliografiske data inn i meningsfulle sammenhenger, og lage forbindelser mellom dataene, slik at brukerne kan følge opptrukne logiske spor som vi lager, og som baner vei i vellinga (les: katalogen).
… Men med linked data tenker man større (større velling..les: hele web), og dessuten ligger det i begrepet at
dataene er registrert i et bestemt web-vennlig format. Det finnes flere formater som er regnet som web-vennlige.
Vi har lenge hatt tesauruser/klassifikasjonssystemer som det ypperste innen emne (i motsetning til «frie emneord»),
nå er det «ontologier», som er mantraet.
En ontologi KAN defineres som det samme som en tesaurus/et klass-system.
Men vanligvis legges det i begrepet ontologi at det også skal være i et web-vennlig format.
Dessuten pleier man å regner med flere typer relasjoner i en ontologi enn i en tesaurus.
Her er det snakk om hvordan man definerer begrepene.
For de som er interessert i Linked data, så er kanskje denne lenken brukandes som et sted å begynne:
http://www.jbi.hio.no/bibin/KoG31/2009/forelesninger/linkeddata.html
Ellers hadde NKKI en seanse om dette temaet på bibliotekmøtet i Hamar i år:
http://www.nb.no/fag/kompetansesenter/kunnskapsorganisering/nkki/aktuelt
Sigrun
2 Comments | KORG | Permalink
Posted by bubak

